Overview
-
What is GlusterFS?
-
Terms
-
GlusterFS Volume Type
-
Accessing Data - Client
-
Other Feature
What is GlusterFS?
-
Distributed scalable network filesystem
-
Automatic failover
-
Without a centralized metadata server – Fast file access
-
No Hot-Spots/Bottlenecks – Elastic Hashing Algorithm
-
XFS file system format to store data (ext3, ext4, ZFS, btrfs)
-
NFS, SMB/CIFS, GlusterFS(POSIX compatible)
-
How Does GlusterFS Work Without Metadata
-
All storage nodes have an algorithm built-in
-
All native clients have an algorithm built-in
-
Files are placed on a brick(s) in the cluster based on a calculation
-
Files can then be retrieved based on the same calculation
-
For non-native clients, the server handles retrieval and placement
-
Term
Elastic Hashing Algorithm
Every folder in a volume is assigned a equal segment of the 32bit number space across bricks.
For example, each folder across 12 bricks,
brick1 = 0- 357913941
brick2 = 357913942 – 715827883
brick3 = 715827884 – 1073741823
…brick12 = 3937053354 – 4294967295
Every folder and sub-folder gets the full range, 0 – 4294967295.
The EHA hashes the name of the file being read | written.
ex) ………\GlusterFSrules.txt = 815827884
We use the Davies-Meyer hash.
The file is read | written on the brick that matches the path and filename hash.
The avalanche effect of a hashing algorithm prevents hotspots.
Regardless of the similarities between filenames/path the hash result is sufficiently different.
Additional, redundant steps are taken to prevent hotspots.
Adding a brick to a volume updates the EHA graph on each node.
Running a volume rebalance after adding a brick physically moves files to match the new EHA graph. Adding a brick (GlusterFS volume add brick) without running a rebalance results in new files being written to the new bricks and link files being created on first access for existing files. This can be slow and isn’t recommended.
Brick
A brick is the combination of a node and a file system.
ex) Hostname: /Directoryname
Each brick inherits limits of the underlying filesystem(ext3/ext4/xfs)
No limit to the number bricks per node.
Gluster operates at the brick level, not at the node level.
Ideally each brick in a cluster should be the same size.
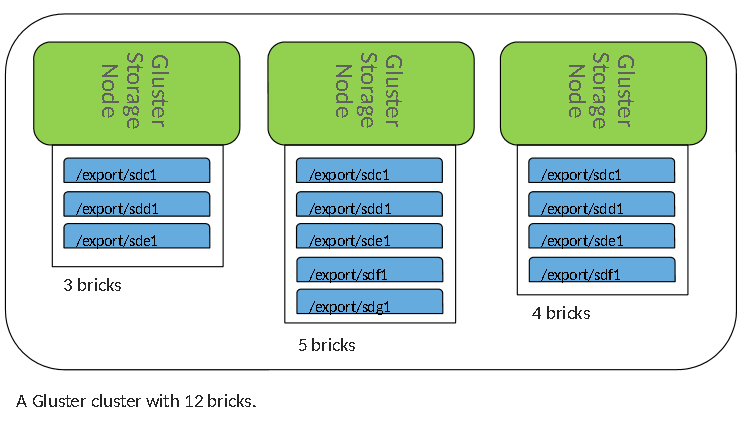
Cluster
A set of Gluster nodes in a trusted pool
Trusted Pool
Storage nodes that are peers and associated in a single cluster.
Node
A single Gluster node in a cluster.
Self Heal
Self-heal is process of self-correcting mechanism built inside GlusterFS. Self-heal process is initiated when ‘client’ detects discrepancies in directory structure, directory metadata, file metadata, file sizes etc. This detection process is initiated during the first access of such a corrupted directory or files.
Split Brain
This is a scenario which happens in a replicated volume when there is a network partition from the client perspective. Resulting in wrong attributes on files which are essential for ‘Gluster’ for its volume consistency and making files available This results in a manual intervention by user/customer to find the old copy and remove it from the back end. Gluster will then perform a “self heal” to sync both the copies.
GlusterFS volume Type
Distributed
No data redundancy
Failure of a brick results in data access issues
Distributes files across bricks in the volume
Cuts hardware, software costs in half.
Failure of a brick or node results in loss of access to the data on those bricks.
Writes destined to the failed brick will fail.
Redundant RAID, hardware is strongly recommended.

Replicated / Distributed Replicated
Redundant at the brick level through synchronous writes
High availability
N replicas are supported
Replicates files across bricks in the volume
Failure of a brick or node does not affect I/O.
Failure of a brick or node results in loss of access to the data on those bricks.
Writes destined to the failed brick will success.
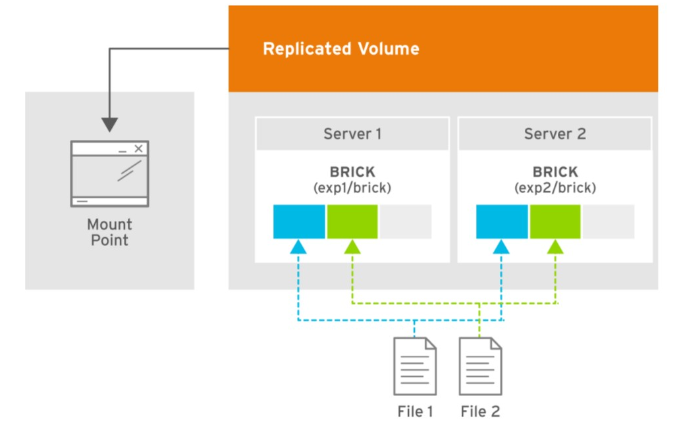

Arbitrated Replicated
High availability and less disk space required
N replicas are supported
Similar to a two-way replicated volume, in that it contains two full copies of the files in the volume. However, volume has an extra arbiter brick for every two data bricks in the volume
Arbiter bricks do not store file data, only store file names, structure, and metadata.
Arbiter bricks use client quorum to compare metadata on the arbiter with the metadata of the other nodes to ensure consistency in the volume and prevent split-brain conditions


Dispersed / Distributed Dispersed
Erasure Coding(EC)
Limited use case(scratch space, very large files, some HPC)
Problems with small files
Disperses the file’s data across the bricks in the volume
Based on erasure coding.
This allows the recovery of the data stored on one or more bricks in case of failure.
n = k + m (n= total number of bricks, k=require bricks, m=out of bricks for recovery)
requires less storage space when compared to a replicated volume

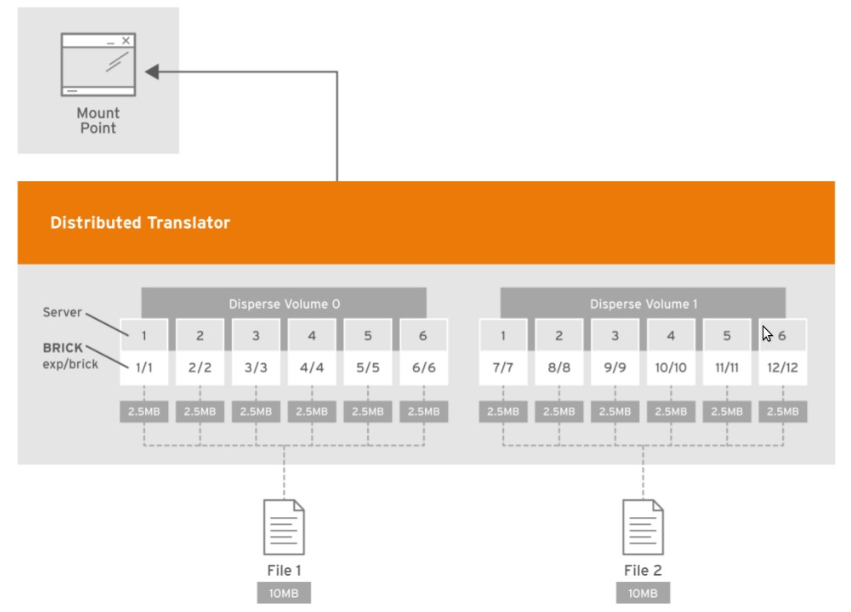
Accessing Data – Client
Native Client
FUSE-based client running in user space.
NFS
NFS ACL v3 is supported
SMB
The Server Message Block (SMB) protocol can be used to access Red Hat Gluster Storage volumes by exporting directories in GlusterFS volumes as SMB shares on the server



Other feature
Geo-replication
Geo-replication provides a distributed, continuous, asynchronous, and incremental replication service from one site to another over Local Area Networks (LANs), Wide Area Networks (WANs), and the Internet

Managing Tiering
Hot tier, cold tier

Security
Enabling Management Encryption
Enabling I/O encrypt ion for a Volume
Disk Encryption
Set up SELinux
Managing Containerized Red Hat Gluster Storage
Used docker
Managing Directory Quotas
Set limits on disk space used by directories or the volume
Supported hardlimit, softlimit
Snapshot
Enables you to create point-in-time copies
Users can directly access Snapshot copies which are read-only to recover from accidental deletion, corruption, or modification of the data.
'Software Defined Storage' 카테고리의 다른 글
| CEPH-Cluster 확장을 위한 이유와 시기에 대한 고찰 (0) | 2020.08.17 |
|---|---|
| Ceph Use Case (0) | 2020.08.13 |
| Ceph Overview (0) | 2020.08.13 |
| Gluster Use Case (0) | 2020.08.12 |
| Why choose Software Defined Storage? (0) | 2020.08.04 |